巴斯克地区大学:一种强大的用于完全无监督跨语言映射词嵌入的自学习方法
你和“懂AI”之间,只差了一篇论文
很多读者给芯君后台留言,说看多了相对简单的AI科普和AI方法论,想看点有深度、有厚度、有眼界……以及重口味的专业论文。
为此,在多位AI领域的专家学者的帮助下,我们解读翻译了一组顶会论文。每一篇论文翻译校对完成,芯君和编辑部的老师们都会一起笑到崩溃,当然有的论文我们看得抱头痛哭。
同学们现在看不看得懂没关系,但芯君敢保证,你终有一天会因此爱上一个AI的新世界。
读芯术读者论文交流群,请加小编微信号:zhizhizhuji。等你。
这是读芯术解读的第109篇论文
ACL 2018 Long Papers
一种强大的用于完全无监督跨语言映射词嵌入的自学习方法
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
巴斯克地区大学
University of the Basque
本文是来自巴斯克地区大学发表于ACL 2018会议的文章,针对无监督跨语言映射词嵌入任务中初始化阶段中的不足,提出一种无监督的初始化方法,并结合一套强大的自学习算法来逐渐优化映射,在众多的知名测试场景中进行实验,并超越了先前的监督系统,证明了该方法的有效性。

1 引言
跨语言嵌入映射已经被证明是双语词嵌入的有效方法。基本的想法是独立的使用不同语言训练嵌入单语语料库,然后通过线性变换将他们映射到共享空间。绝大多数的嵌入式映射方法依赖于小型种子字典,但是在最近对抗性的训练在完全无监督的环境中产生了较好的结果,然而先前的研究往往只能在关联较为密切的语言中获得较好结果,当进入更加现实的情景时却产生不出具有意义的结果。而后又有研究表明,迭代自学习方法能够从非常小的种子字典引导高质量的映射,但是当初始解决方法不够好时,自学习方法会陷入较差的局部结果,导致训练失败。
本文提出一种新的无监督方法来构建一个不需要种子字典的初始化解决方案。根据观察结果,给出词汇表中所有单词的相似度矩阵,每个单词都有不同的相似性分布值。两个不同语言的等价词应该拥有相似性的分布,本文基于这个事实来诱导初始的单词集配对。通过结合以上的初始化方法和强大的自学习方法,可以从弱初始解决方案开始并不断迭代改进映射。最终,通过两者的结合,本文提供一套完全无监督的在实际场景中有效的跨语言映射方法,在所有的测试案例中都收敛到一个好的解决方案,并在双语字典词典提取中设置了一种新的先进技术,超越了之前的监督方法。
2 模型
本文提出了一种新的无监督方法来构建一个不需要种子字典的初始解决方案。基于观察,给定词汇表中所有单词的相似矩阵,每个单词都具有不同的相似值分布。在不同语言中的同一对词语应该具有相似的分布,可以以此作为依据来引导初始化单词配对,如下图所示。

文章将以上提到的初始化方法和一种健壮的自学习方法结合,能够从弱的初始解开始,逐步迭代改进映射。
· 参数表示
Z和X分别表示两种语言中独立训练好的词嵌入矩阵。行代表一个词的词向量,列代表词向量的第几维。这里中Xj和Zj之间、Xi和Zi之间并没有任何的对应关系。这时就需要一个转换矩阵Wx、Wz来使XWx和ZWz在同一个向量空间。同时有叙述矩阵D,Dij = 1时代表目标语言中的第j个单词是源语言中第i个单词的翻译。
· 问题描述
针对以上的构想,需要完成:将X中的i行和Z中的i行、X中的j行和Z中的j行,进行对应。如何对D进行初始化并且要设置怎样的更新策略、采用怎样的目标函数,如何通过目标函数求出Wx和Wz 。
· 实施流程
A. 预处理
首先对每个单词的词向量做归一化,再对词向量的每一列去均值,最后再进行一次归一化处理。
B. 初始化
首先进行假设,目标语言和源语言词向量虽然是独立的,但是其分布的形态却十分相似。假设源语言和目标语言的字典大小一致,维度却不一致。通过Mx = XXT、Mz =ZZT求相似矩阵,Mx[i,j]代表了target 语言中第i个和第j个单词的相似度,分别将Mx和Mz的每一列顺序变成Sorted(Mx)和Sorted(Mz),这样就解决了列之间的关系,对于sorted(Mx)的每i行,都可以再sorted(Mz)中寻找到第j行跟其相似度最高的项,表明其是相同语意的可能性比较大,为相互的翻译,D的初始化问题就被解决了。
C. 自学习:
1. 目标函数

求得Wx =U,Wz=V,且U与V通过奇异值分解得到USVT = XTDZ。

在进行初始化后,循环以上1.2步骤,直至收敛。
· 随机字典归纳
为了鼓励更广泛的探索搜索空间,我们使字典归纳随机保留一些元素随机在具有概率的相似性矩阵中p,并将其余的设置为0。
· 基于频率的词汇cutoff
相似度矩阵的大小相对于词汇表的大小呈二次方增长。这不仅增加了计算它的成本,而且还使得可能的解决方案的数量呈指数增长,可能会使优化问题变得更加困难。我们建议将字典归纳过程限制为每种语言中k个最常用的单词,其中我们发现k = 20,000在实践中运作良好。
· CSLS检索
Dinu等人表明最近邻居受到hubness问题的困扰。文章采用Conneau等人的跨域相似性局部缩放(CSLS)来解决此问题。
· 双向字典归纳
当字典从源语言被引入目标语言时,并非所有目标语言单词都会出现在其中,并且一些将出现多次。文章作者认为这可能会加剧局部最优的问题,为了缓解这个问题并鼓励多样性,作者引入字典。从两个方向归纳字典,并进行相应的连接,D = DXZ + DZX。
3 实验分析
本文进行了全面的结果对比,得到了极为出色的数据表现。
下表展示了其采用的 Zhang et al以及Coneau et a两个数据集的结果。

下表使用了更加有挑战性的来自 Dinu et al和Artetxe et al的数据集。
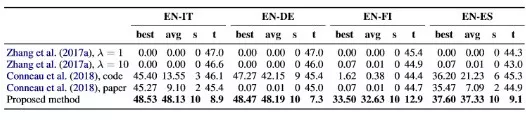
下表比较了与其他学者使用监督学习方法的领先工作。

4 结论
结果表明,本文的方法在所有情况下都取得了成功,为以前关于无监督和监督映射的所有工作提供了最佳结果。
消融分析表明,本文的初步解决方案有助于在没有监督语料的情况下进行自学。为了使自学习能力稳健,我们还在字典归纳中添加了随机性,使用CSLS而不是最近邻居,并生成了双向字典。使用较小的中间词汇表并重新加权最终解决方案,结果也得到了改善。
将来,希望将方法从双语扩展到多语言方案,并通过合并较长短语的嵌入来超越单词级别。
论文下载链接:

留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
~全文结束~


